
Comparing AWS Glue and EMR
Glue and EMR (Elastic MapReduce) are two AWS services that offer overlapping capabilities. So, when should you use one versus the other. In this article, we will provide an overview of the features and capabilities of both and provide some guidance to help inform your choice.
While both of these services provide ETL (Extract Transform Load) capabilities, there are some fundamental differences in the way that the services operate. Let’s start with an overview of some of the features of each.
AWS Glue
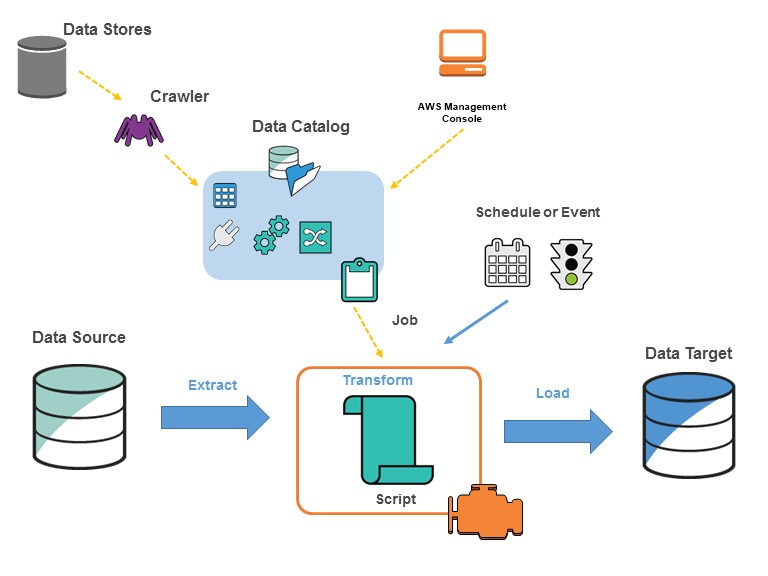
AWS Glue is a pay per use service. It is serverless and requires very little infrastructure set up. It automates much of the effort involved in writing, executing and monitoring ETL jobs. A UI is provided for job scheduling and monitoring. If your data is structured you can take advantage of Crawlers which can infer the schema, identify file formats and populate metadata in Glue’s Data Catalogue. Based on your specified ETL criteria, Glue can even generate Python or Scala code automatically.
AWS EMR
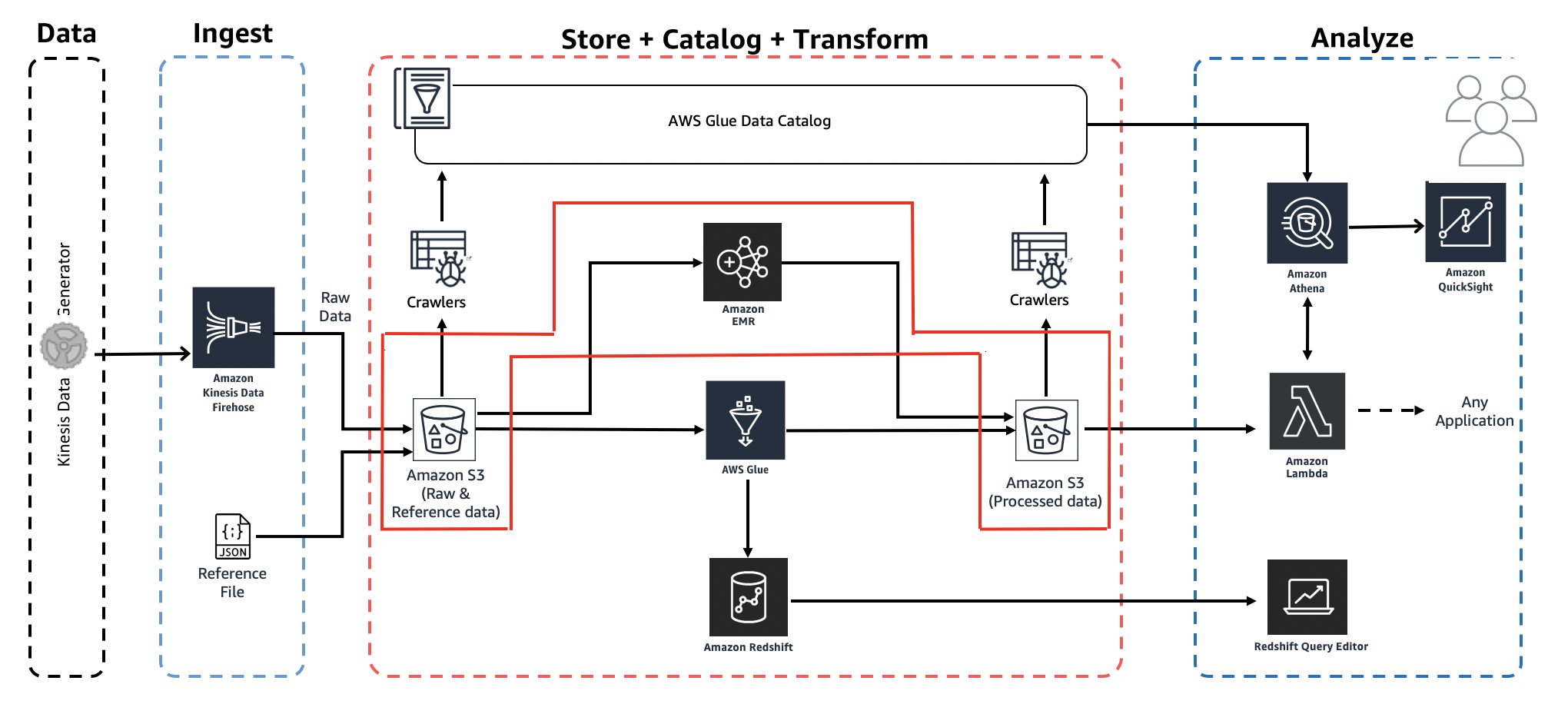
In comparison, EMR is a platform that is designed to provide a high level of flexibility in how you process and analyse huge amounts of data. It is a managed service where you configure your own cluster of EC2 instances. You have complete control over the configuration and can install Apache Hadoop components. This makes EMR an incredibly powerful and flexible tool but the tradeoff is that it is a great deal more complex to set up, configure and manage than Glue. It covers a broad range of use cases and can be used to run machine learning jobs that leverage the EMR TensorFlow library. SQL queries can be executed on EMR Presto. EMR’s can even integrate with streaming applications such as AWS Kinesis.
So, EMR can do everything that Glue can do and then some. However, the initial effort investment in setup will be considerably more with EMR. Cost is another consideration. The development cost of setting up you data pipelines with EMR will be greater than with Glue, although the ongoing operation cost may be lower if your pipelines run frequently or continuously. Glue is generally more expensive than EMR on a cost per minute basis but if your pipelines run less frequently the total costs of a pay per use service may be more economical. This AWS blog post provides some data on how one high usage customer achieved a significant cost reduction by migrating from Glue to EMR.
There are currently only 3 Glue worker types:
- Standard
- G.1X
- G.2X
Even the largest, G2.X provides a maximum of 32GB of executor memory. While this is unlikely to be a barrier for the majority of use cases, it should be born in mind. For example, unzipping very large zip files can lead to out of memory failures. While one would argue that this is a failure of zip file algorithms and there are usually better alternatives, we are often not in control of our big data sources. When we exhaust the memory of a Spark Executor, the job will simply fail. EMR, while not solving the fundamental problem, at least makes the full range of AWS instance types available.
Comparing Use Cases
As a mental map, you can think of EMR as “Hadoop with ecosystems (including spark)”, and Glue as only “Spark ETL with a Hive metastore”. So, EMR will provide direct access to your low level Hadoop environments and greater flexibility in using tools beyond Spark.
For straightforward ETL jobs, we would generally recommend you explore using AWS Glue. It
- allows you to focus on your ETL job and not worry about configuring and managing the underlying compute resources
- takes a data first approach that allows you to focus on the data properties and transformations to a format from which you can quickly derive business insights
- generates an integrated data catalog that makes metadata available for ETL as well as querying from other AWS services such as Athena
- monitors your ETL jobs to greatly simplify job maintenance
- automatically sends logs to CloudWatch, integrating with other metrics and providing a one stop shop for monitoring and alerting
We would only recommend you reach for EMR if the complexity of your requirement exceeds what Glue can offer or when intensive or high-frequency jobs create an economic argument for cost reduction efforts. It should be noted that EMR sends its logs to S3 by default. Although it is possible to install the CloudWatch agent via EMR’s bootstrap configuration, it is not the straightforward logging and monitoring experience that you get with Glue.
Conclusion
If you are getting started with Data pipelines and ETL jobs for the first time, go with Glue. It’s an easier entry into the large data processing world. Then, as long as your workloads remain relatively low and/or frequency is not extremely high, stick with Glue. You would need extremely high loads before the operational cost reduction of EMR would outweigh the development deployment cost efficiencies of Glue. Of course, there is also the possibility that your choice will be dictated by use cases that require some of the more advanced capabilities of EMR that Glue simply doesn’t cover.
In the longer run, you may find yourself using both tools, Glue for certain ad-hoc tasks that you want to stand up quickly and EMR for larger production runs. They might even co-exist. For example, Glue can act as the ETL framework to source and transform data, storing it to S3 and maintaining table definitions of those data sets in Glue Catalog. EMR can then consume those data sets from S3 using EMRFS and Glue Catalog.
Please, get in touch if you would like to discuss data processing with us.